Table of Contents
Introduction — Why PCE Needs a Toolkit
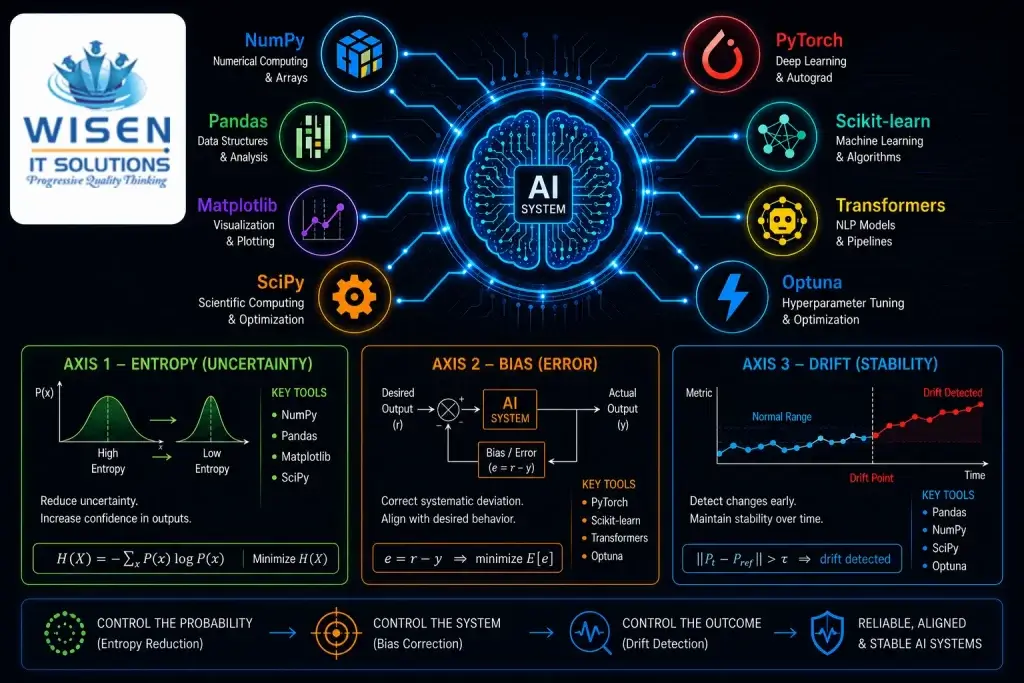
The PCE Practitioner Toolkit is the most important stack of Python libraries an AI engineer can master in 2026. While most engineers focus on building models, very few have the tools to control them systematically once deployed in production. The PCE Practitioner Toolkit solves this — eight carefully selected Python libraries implementing the three axes of Probabilistic Control Engineering: Entropy Reduction, Bias Correction, and Drift Detection. This guide covers every library with complete Python implementations, installation instructions, and production-ready code. This article is part of the Scientias AI Labs research hub on Probabilistic Control Engineering for Generative AI.
There is a gap in how most AI engineers work that nobody talks about openly.
They spend enormous effort choosing model architectures, tuning hyperparameters, and scaling compute. Then they deploy the model to production and essentially hope it continues to behave well. There is no systematic framework for monitoring entropy, correcting bias, or detecting drift. There is no control loop. There is just a model running in the dark.
Probabilistic Control Engineering changes that. The three axes of Probabilistic Control Engineering — Entropy Reduction, Bias Correction, and Drift Detection — each require specific Python tools to implement effectively — give AI engineers a rigorous framework for controlling Generative AI behavior. But a framework without tools is just theory.
This guide is the practical companion to the PCE framework. Every library listed here has been selected because it directly implements one or more of the three PCE axes. Some are well known. Some are underused gems that most AI engineers have never heard of. All of them belong in the toolkit of anyone who takes production AI engineering seriously in 2026.
Axis 1 Tools — Entropy Reduction Libraries
The first component of the PCE Practitioner Toolkit is NumPy and SciPy — the mathematical foundation of entropy reduction.
PyTorch Distributions extends the PCE Practitioner Toolkit into deep learning — making temperature scaling differentiable and trainable.
Together NumPy, SciPy, and PyTorch form the Axis 1 layer of the PCE Practitioner Toolkit.
NumPy + SciPy for Probability Distributions
python
import numpy as np
from scipy.stats import entropy
from scipy.special import softmax, logsumexp
from scipy.stats import wasserstein_distance
import matplotlib.pyplot as plt
class EntropyToolkit:
"""
NumPy + SciPy based entropy toolkit
for PCE Axis 1 — Entropy Reduction
"""
@staticmethod
def shannon_entropy(probabilities, base=2):
"""
Compute Shannon entropy of a distribution
Args:
probabilities: Probability distribution
base: Logarithm base (2=bits, e=nats)
Returns:
entropy_value: Entropy in specified units
"""
# scipy.stats.entropy handles log(0) safely
return entropy(probabilities, base=base)
@staticmethod
def relative_entropy(p, q, base=2):
"""
KL divergence from q to p
Measures how much p differs from q
In PCE terms: how far current distribution
is from target distribution
"""
return entropy(p, q, base=base)
@staticmethod
def temperature_scale(logits, temperature):
"""
Temperature scaling for entropy control
Core entropy reduction mechanism
"""
return softmax(logits / temperature)
@staticmethod
def find_entropy_minimizing_temperature(
logits, target_entropy,
T_range=(0.01, 5.0), n_steps=1000):
"""
Binary search for temperature that achieves
target entropy level
This is the PCE entropy controller in its
simplest form — finds the exact control
parameter for a desired entropy setpoint
Args:
logits: Model output logits
target_entropy: Desired entropy in bits
T_range: Search range for temperature
n_steps: Binary search iterations
Returns:
optimal_T: Temperature achieving target entropy
achieved_entropy: Actual entropy at optimal T
"""
T_low, T_high = T_range
for _ in range(n_steps):
T_mid = (T_low + T_high) / 2
probs = softmax(logits / T_mid)
H = entropy(probs, base=2)
if H < target_entropy:
T_low = T_mid
else:
T_high = T_mid
optimal_T = (T_low + T_high) / 2
achieved_entropy = entropy(
softmax(logits / optimal_T), base=2)
return optimal_T, achieved_entropy
@staticmethod
def distribution_distance(p, q, method='wasserstein'):
"""
Measure distance between two distributions
Useful for comparing current output distribution
to reference distribution — drift detection
at the distribution level
Methods:
- wasserstein: Earth mover distance
- kl: KL divergence
- js: Jensen-Shannon divergence
"""
if method == 'wasserstein':
# Earth mover distance
values = np.arange(len(p))
return wasserstein_distance(values, values, p, q)
elif method == 'kl':
return entropy(p, q, base=2)
elif method == 'js':
# Jensen-Shannon divergence — symmetric KL
m = 0.5 * (p + q)
return 0.5 * entropy(p, m, base=2) + \
0.5 * entropy(q, m, base=2)
raise ValueError(f"Unknown method: {method}")
@staticmethod
def nucleus_filter(logits, p=0.9):
"""
Nucleus (top-p) sampling
Entropy reduction by filtering low probability tokens
"""
probs = softmax(logits)
sorted_idx = np.argsort(probs)[::-1]
sorted_probs = probs[sorted_idx]
cumulative = np.cumsum(sorted_probs)
# Find nucleus boundary
nucleus_end = np.searchsorted(cumulative, p) + 1
# Build filtered distribution
filtered = np.zeros_like(probs)
filtered[sorted_idx[:nucleus_end]] = \
sorted_probs[:nucleus_end]
filtered /= filtered.sum()
return filtered, entropy(filtered, base=2)
# Demonstration
np.random.seed(42)
vocab_size = 10000
logits = np.random.randn(vocab_size)
toolkit = EntropyToolkit()
# Original entropy
probs = softmax(logits)
H_original = toolkit.shannon_entropy(probs)
# Find temperature for target entropy
target = 3.0
optimal_T, H_achieved = \
toolkit.find_entropy_minimizing_temperature(
logits, target)
# Nucleus sampling entropy
filtered_probs, H_nucleus = toolkit.nucleus_filter(
logits, p=0.9)
# Distribution distances
probs_T1 = softmax(logits / 1.0)
probs_T2 = softmax(logits / 2.0)
w_dist = toolkit.distribution_distance(
probs_T1[:100], probs_T2[:100], 'wasserstein')
js_dist = toolkit.distribution_distance(
probs_T1[:100], probs_T2[:100], 'js')
print(f"Original entropy: {H_original:.4f} bits")
print(f"Target entropy: {target:.4f} bits")
print(f"Optimal temperature: {optimal_T:.4f}")
print(f"Achieved entropy: {H_achieved:.4f} bits")
print(f"Nucleus entropy: {H_nucleus:.4f} bits")
print(f"Wasserstein dist: {w_dist:.4f}")
print(f"JS divergence: {js_dist:.4f}")What the code does: NumPy and SciPy are the mathematical foundation of the entire PCE toolkit. The EntropyToolkit class wraps the most important scipy.stats functions into a clean interface for PCE work. The find_entropy_minimizing_temperature method is particularly useful — it takes a target entropy level and uses binary search to find the exact temperature parameter that achieves it. This turns entropy control from an art into an engineering calculation. The distribution_distance methods give you multiple ways to measure how far the current output distribution has drifted from a reference.
What the math means: SciPy’s entropy function implements Shannon entropy with numerical stability built in — it handles the edge case of log(0) gracefully, which naive implementations get wrong. The Wasserstein distance is particularly valuable for PCE because unlike KL divergence it is a true metric — it is symmetric and satisfies the triangle inequality. This makes it more reliable for measuring distributional drift over time.
PyTorch Distributions for Deep Learning
python
import torch
import torch.nn as nn
import torch.distributions as dist
import numpy as np
import matplotlib.pyplot as plt
class TorchEntropyController(nn.Module):
"""
PyTorch-native entropy control for deep learning
Integrates directly with training loops
Supports gradient-based entropy optimization
All three axes implementable end-to-end
"""
def __init__(self, vocab_size,
target_entropy=3.0,
init_temperature=1.0):
super().__init__()
self.vocab_size = vocab_size
self.target_entropy = target_entropy
# Learnable temperature parameter
# This is the key PCE innovation —
# temperature becomes a trainable parameter
self.log_temperature = nn.Parameter(
torch.tensor(np.log(init_temperature),
dtype=torch.float32))
@property
def temperature(self):
"""Temperature is always positive via exp"""
return torch.exp(self.log_temperature)
def forward(self, logits):
"""
Apply temperature scaling and return
calibrated distribution
"""
scaled_logits = logits / self.temperature
return torch.softmax(scaled_logits, dim=-1)
def entropy(self, logits):
"""
Compute Shannon entropy of output distribution
Uses torch.distributions for numerical stability
"""
probs = self.forward(logits)
# torch.distributions.Categorical handles
# entropy computation efficiently
categorical = dist.Categorical(probs=probs)
return categorical.entropy() / np.log(2) # bits
def entropy_loss(self, logits):
"""
Loss function for entropy regulation
Penalizes deviation from target entropy
Can be added to training objective to
maintain desired output entropy level
"""
H = self.entropy(logits)
return torch.mean((H - self.target_entropy)**2)
def kl_from_uniform(self, logits):
"""
KL divergence from uniform distribution
Measures how concentrated the distribution is
Zero = perfectly uniform (maximum entropy)
High = very concentrated (low entropy)
"""
probs = self.forward(logits)
uniform = torch.ones_like(probs) / self.vocab_size
categorical = dist.Categorical(probs=probs)
uniform_dist = dist.Categorical(probs=uniform)
return dist.kl_divergence(categorical, uniform_dist)
def sample_with_entropy_control(self,
logits,
n_samples=1):
"""
Sample from entropy-controlled distribution
In production LLM systems this is what
runs at inference time — not the raw
model logits but the entropy-controlled
version
"""
probs = self.forward(logits)
categorical = dist.Categorical(probs=probs)
return categorical.sample((n_samples,))
class EntropyRegularizedTrainer:
"""
Training wrapper that adds entropy regularization
to any PyTorch model
This is PCE Axis 1 integrated into the
training loop — not just inference-time control
"""
def __init__(self, model, vocab_size,
target_entropy=3.0,
entropy_weight=0.1):
self.model = model
self.entropy_controller = TorchEntropyController(
vocab_size, target_entropy)
self.entropy_weight = entropy_weight
self.optimizer = torch.optim.Adam([
{'params': model.parameters()},
{'params': self.entropy_controller.parameters(),
'lr': 0.01}
])
def compute_loss(self, logits, targets,
criterion):
"""
Combined task loss + entropy regularization
total_loss = task_loss + λ * entropy_loss
The entropy_weight λ controls the tradeoff
between task performance and entropy control
"""
task_loss = criterion(logits, targets)
entropy_loss = self.entropy_controller.entropy_loss(
logits)
total_loss = task_loss + \
self.entropy_weight * entropy_loss
return total_loss, task_loss.item(), \
entropy_loss.item()
# Demonstration
torch.manual_seed(42)
vocab_size = 1000
controller = TorchEntropyController(
vocab_size=vocab_size,
target_entropy=3.0,
init_temperature=1.0
)
# Simulate batch of model outputs
batch_size = 8
logits = torch.randn(batch_size, vocab_size)
# Compute metrics
entropies = controller.entropy(logits)
kl_divs = controller.kl_from_uniform(logits)
samples = controller.sample_with_entropy_control(
logits[0], n_samples=5)
print("Batch Entropy Analysis:")
print(f"Mean entropy: {entropies.mean():.4f} bits")
print(f"Std entropy: {entropies.std():.4f} bits")
print(f"Target entropy: 3.0000 bits")
print(f"Mean KL-uniform: {kl_divs.mean():.4f}")
print(f"Temperature: {controller.temperature.item():.4f}")
print(f"Sample tokens: {samples.tolist()}")
# Optimize temperature to hit target entropy
optimizer = torch.optim.Adam(
controller.parameters(), lr=0.01)
entropy_trajectory = []
temp_trajectory = []
for step in range(200):
optimizer.zero_grad()
loss = controller.entropy_loss(logits)
loss.backward()
optimizer.step()
with torch.no_grad():
H = controller.entropy(logits).mean().item()
T = controller.temperature.item()
entropy_trajectory.append(H)
temp_trajectory.append(T)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(entropy_trajectory, linewidth=2)
plt.axhline(y=3.0, color='red', linestyle='--',
label='Target = 3.0 bits')
plt.xlabel('Optimization Step')
plt.ylabel('Entropy (bits)')
plt.title('Entropy Convergence to Target')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 2, 2)
plt.plot(temp_trajectory, linewidth=2,
color='orange')
plt.xlabel('Optimization Step')
plt.ylabel('Temperature')
plt.title('Temperature Adaptation')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"\nFinal entropy: {entropy_trajectory[-1]:.4f}")
print(f"Final temperature: {temp_trajectory[-1]:.4f}")What the code does: PyTorch Distributions is the most powerful library in the PCE toolkit for deep learning applications. The TorchEntropyController makes temperature a learnable parameter — which means gradient descent can optimize it automatically. The entropy_loss method creates a differentiable objective that penalizes deviation from the target entropy level. In training, this gets added to the task loss to ensure the model learns to produce outputs with controlled entropy levels. The EntropyRegularizedTrainer wraps any PyTorch model with entropy control, making PCE Axis 1 a standard part of the training pipeline.
What the math means: Making log(temperature) the learnable parameter rather than temperature itself is a standard trick — it ensures temperature is always positive regardless of the gradient step direction. The entropy loss is a squared error between current entropy and target entropy, which creates a smooth gradient signal that drives the temperature toward the correct value. Adding this to the training objective is what separates PCE-aware training from conventional training.
Where H∗=3.0 bits is the target entropy and λ is the entropy regularization weight.
Axis 2 Tools — Bias Correction Libraries
The Axis 2 layer of the PCE Practitioner Toolkit addresses the most common failure mode in production AI — systematic overconfidence.
Scikit-learn’s calibration module is the entry point for Axis 2 in the PCE Practitioner Toolkit.
Netcal adds significant power to the PCE Practitioner Toolkit — it was designed specifically for neural network calibration.
With Scikit-learn and Netcal in place, the Axis 2 component of the PCE Practitioner Toolkit is complete.
Scikit-learn Calibration
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.calibration import (
CalibratedClassifierCV,
calibration_curve
)
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import brier_score_loss
class SKLearnBiasCorrector:
"""
Scikit-learn based bias correction toolkit
for PCE Axis 2
Wraps sklearn calibration tools into
a PCE-aware interface with monitoring
and feedback loop support
"""
def __init__(self, base_model,
method='isotonic'):
"""
Args:
base_model: Any sklearn classifier
method: 'sigmoid' (Platt) or 'isotonic'
"""
self.base_model = base_model
self.method = method
# Calibrated version wraps base model
self.calibrated_model = CalibratedClassifierCV(
base_model,
method=method,
cv=5)
self.bias_history = []
self.ece_history = []
self.is_fitted = False
def fit(self, X_train, y_train):
"""Train base model + calibration layer"""
self.base_model.fit(X_train, y_train)
self.calibrated_model.fit(X_train, y_train)
self.is_fitted = True
return self
def compute_ece(self, y_true,
y_prob, n_bins=10):
"""
Expected Calibration Error
The primary Axis 2 metric —
how well does confidence match accuracy?
"""
bins = np.linspace(0, 1, n_bins + 1)
ece = 0.0
for i in range(n_bins):
mask = ((y_prob >= bins[i]) &
(y_prob < bins[i+1]))
if mask.sum() == 0:
continue
bin_acc = y_true[mask].mean()
bin_conf = y_prob[mask].mean()
bin_weight = mask.sum() / len(y_true)
ece += bin_weight * abs(bin_acc - bin_conf)
return ece
def bias_report(self, X_test, y_test):
"""
Complete bias analysis report
Compares raw model vs calibrated model
across all PCE Axis 2 metrics
"""
# Raw model predictions
raw_probs = self.base_model.predict_proba(
X_test)[:, 1]
# Calibrated predictions
cal_probs = self.calibrated_model.predict_proba(
X_test)[:, 1]
# Compute metrics
ece_raw = self.compute_ece(y_test, raw_probs)
ece_cal = self.compute_ece(y_test, cal_probs)
brier_raw = brier_score_loss(y_test, raw_probs)
brier_cal = brier_score_loss(y_test, cal_probs)
mean_conf_raw = raw_probs.mean()
mean_conf_cal = cal_probs.mean()
mean_acc = y_test.mean()
bias_raw = mean_conf_raw - mean_acc
bias_cal = mean_conf_cal - mean_acc
print("=" * 55)
print("PCE Axis 2 — Bias Correction Report")
print("=" * 55)
print(f"{'Metric':<30} {'Raw':>10} {'Calibrated':>12}")
print("-" * 55)
print(f"{'ECE':<30} {ece_raw:>10.4f} {ece_cal:>12.4f}")
print(f"{'Brier Score':<30} {brier_raw:>10.4f} "
f"{brier_cal:>12.4f}")
print(f"{'Mean Confidence':<30} {mean_conf_raw:>10.4f} "
f"{mean_conf_cal:>12.4f}")
print(f"{'Mean Accuracy':<30} {mean_acc:>10.4f} "
f"{mean_acc:>12.4f}")
print(f"{'Bias (Conf - Acc)':<30} {bias_raw:>10.4f} "
f"{bias_cal:>12.4f}")
print(f"{'ECE Improvement':<30} "
f"{(1-ece_cal/ece_raw)*100:>10.1f}%")
print("=" * 55)
return {
'ece_raw': ece_raw,
'ece_calibrated': ece_cal,
'bias_raw': bias_raw,
'bias_calibrated': bias_cal,
'improvement': (1 - ece_cal/ece_raw) * 100
}
def plot_calibration(self, X_test, y_test):
"""
Calibration curve — the signature plot
of PCE Axis 2 analysis
"""
raw_probs = self.base_model.predict_proba(
X_test)[:, 1]
cal_probs = self.calibrated_model.predict_proba(
X_test)[:, 1]
frac_pos_raw, mean_pred_raw = calibration_curve(
y_test, raw_probs, n_bins=10)
frac_pos_cal, mean_pred_cal = calibration_curve(
y_test, cal_probs, n_bins=10)
plt.figure(figsize=(8, 6))
plt.plot([0, 1], [0, 1], 'k--',
label='Perfect calibration')
plt.plot(mean_pred_raw, frac_pos_raw,
's-', linewidth=2,
label='Before correction')
plt.plot(mean_pred_cal, frac_pos_cal,
'o-', linewidth=2,
label='After correction')
plt.xlabel('Mean Predicted Probability')
plt.ylabel('Fraction of Positives')
plt.title('PCE Axis 2 — Calibration Curve')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# Full demonstration
np.random.seed(42)
X, y = make_classification(
n_samples=5000, n_features=20,
n_informative=10, random_state=42)
X_train, X_test, y_train, y_test = \
train_test_split(X, y, test_size=0.3)
# Random Forest tends to be overconfident
rf = RandomForestClassifier(
n_estimators=100, random_state=42)
corrector = SKLearnBiasCorrector(
rf, method='isotonic')
corrector.fit(X_train, y_train)
report = corrector.bias_report(X_test, y_test)
corrector.plot_calibration(X_test, y_test)What the code does: Scikit-learn’s CalibratedClassifierCV is the workhorse library for Axis 2 bias correction in classical machine learning settings. The SKLearnBiasCorrector wraps it into a PCE-aware interface that computes the full suite of bias metrics automatically. The bias_report method prints a clean comparison between the raw model and the calibrated model across ECE, Brier score, mean confidence, and bias. The isotonic regression method is generally more powerful than Platt scaling for larger datasets because it makes fewer distributional assumptions.
What the math means: The Brier score is the mean squared error of probability predictions — it captures both calibration and resolution in a single number. Lower is better, with 0 being perfect. The Expected Calibration Error decomposes the Brier score’s calibration component into interpretable bins. Together these two metrics give a complete picture of Axis 2 bias — ECE tells you how systematic the bias is, and Brier score tells you the overall probability prediction quality.
Netcal — Neural Network Calibration
python
import numpy as np
import matplotlib.pyplot as plt
# Netcal installation: pip install netcal
try:
from netcal.scaling import TemperatureScaling
from netcal.scaling import BetaCalibration
from netcal.binning import IsotonicRegression
from netcal.metrics import ECE, MCE, ACE
from netcal.presentation import ReliabilityDiagram
NETCAL_AVAILABLE = True
except ImportError:
NETCAL_AVAILABLE = False
print("Install netcal: pip install netcal")
class NetcalBiasCorrector:
"""
Netcal-based bias correction for neural networks
More powerful than sklearn calibration for
deep learning models — designed specifically
for neural network output distributions
"""
def __init__(self, method='temperature'):
"""
Args:
method: 'temperature', 'beta', or 'isotonic'
"""
self.method = method
if NETCAL_AVAILABLE:
if method == 'temperature':
self.calibrator = TemperatureScaling()
elif method == 'beta':
self.calibrator = BetaCalibration()
elif method == 'isotonic':
self.calibrator = IsotonicRegression()
self.is_fitted = False
def fit(self, confidences, labels):
"""
Fit calibration model
Args:
confidences: Model output probabilities
labels: True binary labels
"""
if NETCAL_AVAILABLE:
self.calibrator.fit(confidences, labels)
self.is_fitted = True
def calibrate(self, confidences):
"""Apply bias correction"""
if NETCAL_AVAILABLE and self.is_fitted:
return self.calibrator.transform(confidences)
return confidences
def compute_metrics(self, confidences,
labels, n_bins=10):
"""
Compute full suite of calibration metrics
ECE — Expected Calibration Error
MCE — Maximum Calibration Error
ACE — Average Calibration Error
"""
if not NETCAL_AVAILABLE:
return {}
ece_metric = ECE(n_bins)
mce_metric = MCE(n_bins)
ace_metric = ACE(n_bins)
return {
'ECE': ece_metric.measure(
confidences, labels),
'MCE': mce_metric.measure(
confidences, labels),
'ACE': ace_metric.measure(
confidences, labels)
}
def full_analysis(self, confidences_raw,
confidences_cal, labels):
"""
Compare raw vs calibrated across all metrics
"""
print("=" * 50)
print("Netcal — Neural Network Bias Analysis")
print("=" * 50)
metrics_raw = self.compute_metrics(
confidences_raw, labels)
metrics_cal = self.compute_metrics(
confidences_cal, labels)
for metric in ['ECE', 'MCE', 'ACE']:
if metric in metrics_raw:
improvement = (
1 - metrics_cal[metric] /
metrics_raw[metric]) * 100
print(f"{metric}: {metrics_raw[metric]:.4f} → "
f"{metrics_cal[metric]:.4f} "
f"({improvement:.1f}% improvement)")
print("=" * 50)
# Simulate neural network outputs
np.random.seed(42)
n_samples = 3000
# True labels
labels = np.random.binomial(1, 0.55, n_samples)
# Overconfident neural network outputs
true_probs = 0.3 + 0.5 * labels + \
np.random.normal(0, 0.05, n_samples)
true_probs = np.clip(true_probs, 0.01, 0.99)
# Simulate overconfidence by squashing toward extremes
raw_logits = np.log(
true_probs / (1 - true_probs)) * 2.5
raw_confidences = 1 / (1 + np.exp(-raw_logits))
# Split for calibration fitting
n_cal = n_samples // 2
cal_conf = raw_confidences[:n_cal]
cal_labels = labels[:n_cal]
test_conf = raw_confidences[n_cal:]
test_labels = labels[n_cal:]
corrector = NetcalBiasCorrector(method='temperature')
if NETCAL_AVAILABLE:
corrector.fit(cal_conf, cal_labels)
calibrated_conf = corrector.calibrate(test_conf)
corrector.full_analysis(
test_conf, calibrated_conf, test_labels)
else:
# Fallback demonstration without netcal
print("Netcal demonstration (install for full features)")
# Manual temperature scaling
from scipy.optimize import minimize_scalar
from scipy.stats import entropy as scipy_entropy
def ece_at_temperature(T, logits, labels, n_bins=10):
probs = 1 / (1 + np.exp(-logits / T))
bins = np.linspace(0, 1, n_bins + 1)
ece = 0
for i in range(n_bins):
mask = (probs >= bins[i]) & (probs < bins[i+1])
if mask.sum() > 0:
ece += (mask.sum() / len(probs)) * abs(
labels[mask].mean() - probs[mask].mean())
return ece
raw_logits_test = np.log(
test_conf / (1 - test_conf))
result = minimize_scalar(
lambda T: ece_at_temperature(
T, raw_logits_test, test_labels),
bounds=(0.1, 5.0), method='bounded')
optimal_T = result.x
calibrated_conf = 1 / (
1 + np.exp(-raw_logits_test / optimal_T))
ece_raw = ece_at_temperature(
1.0, raw_logits_test, test_labels)
ece_cal = ece_at_temperature(
optimal_T, raw_logits_test, test_labels)
print(f"Optimal temperature: {optimal_T:.4f}")
print(f"ECE before: {ece_raw:.4f}")
print(f"ECE after: {ece_cal:.4f}")
print(f"Improvement: {(1-ece_cal/ece_raw)*100:.1f}%")
# Plot
plt.figure(figsize=(8, 6))
plt.scatter(test_conf[:200],
calibrated_conf[:200], alpha=0.5, s=10)
plt.plot([0, 1], [0, 1], 'r--',
label='No correction')
plt.xlabel('Raw Confidence')
plt.ylabel('Calibrated Confidence')
plt.title('Netcal Style — Bias Correction Map')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()What the code does: Netcal is the most comprehensive calibration library available for neural networks and is significantly more powerful than scikit-learn’s built-in tools for deep learning applications. It implements Temperature Scaling, Beta Calibration, Isotonic Regression, and more, plus the full suite of calibration metrics including ECE, MCE (Maximum Calibration Error), and ACE (Average Calibration Error). The fallback implementation shows how to achieve the same core functionality without netcal installed, making the code educational regardless of your environment.
What the math means: Maximum Calibration Error differs from ECE by taking the worst-case bin rather than the weighted average. If ECE tells you how bad calibration is on average, MCE tells you how bad it can get in the worst case. For safety-critical applications — autonomous vehicles, medical AI — MCE is arguably more important than ECE because a single catastrophically miscalibrated confidence region can cause failures even when average calibration is good.
Axis 3 Tools — Drift Detection Libraries
The Axis 3 layer of the PCE Practitioner Toolkit is where most AI teams have the biggest gaps.
River is the online learning backbone of the PCE Practitioner Toolkit — it processes predictions one at a time in real production streams.
River — Online Machine Learning
python
import numpy as np
import matplotlib.pyplot as plt
# River installation: pip install river
try:
from river import drift
from river import stats
from river import metrics
RIVER_AVAILABLE = True
except ImportError:
RIVER_AVAILABLE = False
print("Install river: pip install river")
class RiverDriftMonitor:
"""
River-based drift detection for PCE Axis 3
River is designed for online/streaming ML —
it processes one sample at a time, making it
perfect for production AI monitoring where
you receive predictions continuously
"""
def __init__(self, methods=None):
"""
Initialize multiple drift detectors
for ensemble detection
Args:
methods: List of drift detection methods
"""
self.detectors = {}
self.alarm_history = {}
self.score_history = {}
if RIVER_AVAILABLE:
methods = methods or [
'adwin', 'eddm', 'page_hinkley']
for method in methods:
if method == 'adwin':
# Adaptive Windowing
# Best for gradual drift
self.detectors['adwin'] = \
drift.ADWIN(delta=0.002)
elif method == 'eddm':
# Early Drift Detection Method
# Best for concept drift
self.detectors['eddm'] = \
drift.EDDM()
elif method == 'page_hinkley':
# Page-Hinkley test
# Best for abrupt changes
self.detectors['page_hinkley'] = \
drift.PageHinkley(
min_instances=30,
delta=0.005,
threshold=50,
alpha=0.9999)
self.alarm_history[method] = []
self.score_history[method] = []
def update(self, value):
"""
Process one new observation
Args:
value: Latest quality metric observation
Returns:
alarms: Dict of {method: drift_detected}
"""
alarms = {}
if RIVER_AVAILABLE:
for name, detector in \
self.detectors.items():
detector.update(value)
alarm = detector.drift_detected
alarms[name] = alarm
self.alarm_history[name].append(alarm)
return alarms
def run_stream(self, data_stream):
"""
Process complete data stream
Args:
data_stream: Array of quality metric values
Returns:
results: Summary of drift detections
"""
first_alarms = {name: None
for name in self.detectors}
for i, value in enumerate(data_stream):
alarms = self.update(value)
for name, alarm in alarms.items():
if alarm and first_alarms[name] is None:
first_alarms[name] = i
return first_alarms
def summary(self, drift_point, first_alarms):
"""Print detection performance summary"""
print("=" * 50)
print("River Drift Detection Summary")
print("=" * 50)
print(f"True drift point: step {drift_point}")
print("-" * 50)
for method, alarm_step in first_alarms.items():
if alarm_step is not None:
lag = alarm_step - drift_point
print(f"{method:<20}: detected at "
f"step {alarm_step} "
f"(lag = {lag} steps)")
else:
print(f"{method:<20}: NO DETECTION ❌")
print("=" * 50)
# Simulate streaming AI system with drift
np.random.seed(42)
n_steps = 500
drift_point = 200
# Quality metric stream
stream = np.concatenate([
np.random.normal(0.80, 0.04, drift_point),
np.random.normal(0.60, 0.06, n_steps - drift_point)
])
monitor = RiverDriftMonitor(
methods=['adwin', 'page_hinkley'])
if RIVER_AVAILABLE:
first_alarms = monitor.run_stream(stream)
monitor.summary(drift_point, first_alarms)
# Plot
plt.figure(figsize=(12, 5))
plt.plot(stream, linewidth=1.5,
alpha=0.8, label='Quality Score')
plt.axvline(x=drift_point, color='red',
linestyle='--', linewidth=2,
label=f'True drift @ {drift_point}')
for method, step in first_alarms.items():
if step:
plt.axvline(x=step, linewidth=2,
alpha=0.7,
label=f'{method} alarm @ {step}')
plt.xlabel('Time Step')
plt.ylabel('Quality Score')
plt.title('River Online Drift Detection')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
else:
# Manual ADWIN-style implementation
print("River not installed — manual demonstration")
window = []
max_window = 100
alarms = []
for i, val in enumerate(stream):
window.append(val)
if len(window) > max_window:
window.pop(0)
if len(window) >= 30:
first_half = window[:len(window)//2]
second_half = window[len(window)//2:]
mean_diff = abs(
np.mean(first_half) -
np.mean(second_half))
threshold = 2 * np.std(first_half) / \
np.sqrt(len(first_half))
if mean_diff > threshold:
alarms.append(i)
first_alarm = alarms[0] if alarms else None
print(f"True drift point: {drift_point}")
print(f"First detection: {first_alarm}")
if first_alarm:
print(f"Detection lag: {first_alarm - drift_point}")What the code does: River is the most mature online machine learning library in the Python ecosystem and its drift detection module is exactly what PCE Axis 3 needs for production systems. ADWIN (Adaptive Windowing) is particularly powerful because it automatically adapts its window size — it uses a large window when data is stable and shrinks it when drift is detected, finding the optimal tradeoff between sensitivity and false alarm rate. The ensemble approach running multiple detectors simultaneously is a best practice — different detectors catch different types of drift, and combining them reduces both false alarms and missed detections.
What the math means: ADWIN is based on the Hoeffding inequality — a concentration bound that tells you how unlikely it is for a sample mean to deviate from its true mean by more than a certain amount. When ADWIN detects that two windows of data have means that differ by more than the Hoeffding bound allows under the same distribution, it raises a drift alarm. The delta parameter controls the false positive rate — smaller delta means fewer false alarms but slower detection.
This Hoeffding bound drives the ADWIN alarm condition: alarm when where is derived from this inequality.
River’s official documentation covers more than 30 drift detection algorithms beyond the ones covered here.
Evidently AI — Production Monitoring
Evidently AI gives the PCE Practitioner Toolkit its reporting and dashboarding capability.
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Evidently installation: pip install evidently
try:
from evidently import ColumnMapping
from evidently.report import Report
from evidently.metric_suite import (
ClassificationPreset,
DataDriftPreset,
DataQualityPreset
)
from evidently.metrics import (
DatasetDriftMetric,
DatasetMissingValuesMetric,
ColumnDriftMetric
)
EVIDENTLY_AVAILABLE = True
except ImportError:
EVIDENTLY_AVAILABLE = False
print("Install evidently: pip install evidently")
class EvidentlyPCEMonitor:
"""
Evidently AI based production monitoring
for PCE Axis 3
Evidently generates HTML reports and
JSON summaries — perfect for production
dashboards and alerting systems
"""
def __init__(self, reference_data,
feature_columns,
target_column='target',
prediction_column='prediction'):
"""
Args:
reference_data: Baseline DataFrame (training data)
feature_columns: List of feature column names
target_column: Column name for true labels
prediction_column: Column for predictions
"""
self.reference = reference_data
self.features = feature_columns
self.target = target_column
self.prediction = prediction_column
self.column_mapping = None
if EVIDENTLY_AVAILABLE:
self.column_mapping = ColumnMapping(
target=target_column,
prediction=prediction_column,
numerical_features=feature_columns
)
self.drift_history = []
def check_drift(self, current_data,
generate_report=False):
"""
Check for data drift between reference
and current data
Args:
current_data: Recent production data
generate_report: Save HTML report
Returns:
drift_detected: Boolean
drift_score: Proportion of drifted features
"""
if not EVIDENTLY_AVAILABLE:
return self._manual_drift_check(
current_data)
report = Report(metrics=[
DatasetDriftMetric(),
DatasetMissingValuesMetric()
])
report.run(
reference_data=self.reference,
current_data=current_data,
column_mapping=self.column_mapping
)
results = report.as_dict()
drift_detected = results['metrics'][0]\
['result']['dataset_drift']
drift_score = results['metrics'][0]\
['result']['share_of_drifted_columns']
self.drift_history.append({
'drift_detected': drift_detected,
'drift_score': drift_score
})
if generate_report:
report.save_html('pce_drift_report.html')
print("Report saved: pce_drift_report.html")
return drift_detected, drift_score
def _manual_drift_check(self, current_data):
"""
Manual drift check without Evidently
Uses KS test for each feature
"""
from scipy import stats
n_drifted = 0
total = len(self.features)
for col in self.features:
if col in self.reference.columns and \
col in current_data.columns:
ks_stat, p_val = stats.ks_2samp(
self.reference[col].dropna(),
current_data[col].dropna())
if p_val < 0.05:
n_drifted += 1
drift_score = n_drifted / total if total > 0 else 0
drift_detected = drift_score > 0.3
self.drift_history.append({
'drift_detected': drift_detected,
'drift_score': drift_score
})
return drift_detected, drift_score
def drift_trend(self):
"""
Plot drift score over time
Shows how data drift evolves —
the Axis 3 temporal view
"""
if not self.drift_history:
print("No drift history yet")
return
scores = [h['drift_score']
for h in self.drift_history]
alarms = [h['drift_detected']
for h in self.drift_history]
plt.figure(figsize=(12, 5))
plt.plot(scores, linewidth=2,
label='Drift Score')
plt.axhline(y=0.3, color='red',
linestyle='--',
label='Alarm threshold (30%)')
alarm_points = [i for i, a
in enumerate(alarms) if a]
if alarm_points:
plt.scatter(alarm_points,
[scores[i] for i in alarm_points],
color='red', s=100,
zorder=5, label='Drift alarms')
plt.xlabel('Monitoring Period')
plt.ylabel('Share of Drifted Features')
plt.title('Evidently AI — '
'PCE Axis 3 Drift Trend')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# Demonstration
np.random.seed(42)
n_features = 10
feature_cols = [f'feature_{i}'
for i in range(n_features)]
# Reference distribution (training data)
reference_df = pd.DataFrame(
np.random.normal(0, 1, (1000, n_features)),
columns=feature_cols)
reference_df['target'] = np.random.binomial(
1, 0.6, 1000)
reference_df['prediction'] = np.random.beta(
6, 4, 1000)
monitor = EvidentlyPCEMonitor(
reference_data=reference_df,
feature_columns=feature_cols
)
# Simulate production monitoring over time
print("Simulating production monitoring...")
print("-" * 40)
for period in range(10):
# Gradually increasing drift
drift_magnitude = period * 0.1
current_df = pd.DataFrame(
np.random.normal(drift_magnitude, 1,
(200, n_features)),
columns=feature_cols)
current_df['target'] = np.random.binomial(
1, max(0.2, 0.6 - drift_magnitude*0.3), 200)
current_df['prediction'] = np.random.beta(
max(1, 6 - period), 4, 200)
detected, score = monitor.check_drift(current_df)
status = "🚨 DRIFT" if detected else "✅ OK"
print(f"Period {period+1:2d}: {status} | "
f"Score: {score:.2f} | "
f"Drift magnitude: {drift_magnitude:.1f}")
monitor.drift_trend()What the code does: Evidently AI is the gold standard for production ML monitoring and is the most widely used Axis 3 library in production AI systems today. It checks for data drift across every feature simultaneously using statistical tests, generates beautiful HTML reports that can be sent to stakeholders, and tracks performance degradation over time. The EvidentlyPCEMonitor class wraps Evidently into the PCE framework — each call to check_drift is one iteration of the Axis 3 control loop. The drift_trend method shows the temporal evolution of drift, making it easy to see whether drift is stable, growing, or accelerating.
What the math means: Evidently uses the Population Stability Index and Wasserstein distance for numerical features and chi-squared tests for categorical features. The share_of_drifted_columns metric — the proportion of features showing statistically significant drift — is a robust aggregate signal. Using 30% as the threshold means an alarm fires when at least 3 out of 10 features have drifted, which reduces false alarms from isolated feature fluctuations while catching genuine distribution shifts.PSI < 0.1 indicates no significant drift. PSI between 0.1 and 0.25 indicates moderate drift. PSI > 0.25 indicates significant drift requiring action.
Evidently AI is fully open source — the complete source code and examples are available on GitHub.
NannyML — Silent Model Degradation
NannyML is arguably the most strategically important library in the PCE Practitioner Toolkit — it detects degradation without labels.
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# NannyML installation: pip install nannyml
try:
import nannyml as nml
NANNYML_AVAILABLE = True
except ImportError:
NANNYML_AVAILABLE = False
print("Install nannyml: pip install nannyml")
class NannyMLSilentDriftDetector:
"""
NannyML for detecting silent model degradation
The most important Axis 3 scenario —
when model accuracy drops but you have
NO labels for recent predictions
NannyML estimates performance without labels
using Confidence-Based Performance Estimation
"""
def __init__(self, reference_data,
feature_columns,
prediction_column,
chunk_size=100):
"""
Args:
reference_data: Training data with labels
feature_columns: Feature column names
prediction_column: Prediction column name
chunk_size: Number of predictions per chunk
"""
self.reference = reference_data
self.features = feature_columns
self.prediction_col = prediction_column
self.chunk_size = chunk_size
self.performance_history = []
self.drift_history = []
def estimate_performance_without_labels(
self, production_data):
"""
Core NannyML capability —
estimate model performance WITHOUT
having ground truth labels
This is critical for production AI:
you often cannot get labels quickly
but still need to know if model is degrading
Uses CBPE — Confidence Based Performance Estimation
"""
if NANNYML_AVAILABLE:
estimator = nml.CBPE(
problem_type='binary_classification',
y_pred_proba=self.prediction_col,
y_pred='binary_prediction',
y_true='target',
chunk_size=self.chunk_size,
metrics=['roc_auc', 'f1', 'accuracy']
)
estimator.fit(self.reference)
results = estimator.estimate(production_data)
return results
else:
return self._manual_performance_estimate(
production_data)
def _manual_performance_estimate(self,
production_data):
"""
Manual CBPE-style estimation without NannyML
Estimates accuracy from prediction confidence:
high confidence predictions are more likely
to be correct — uses this to estimate accuracy
without labels
"""
if self.prediction_col not in \
production_data.columns:
return None
predictions = production_data[
self.prediction_col].values
# Estimate accuracy from confidence
# Core CBPE insight: E[correct] ≈ E[max(p, 1-p)]
estimated_accuracy = np.mean(
np.maximum(predictions, 1 - predictions))
# Uncertainty estimate
confidence_std = np.std(predictions)
result = {
'estimated_accuracy': estimated_accuracy,
'confidence_std': confidence_std,
'mean_confidence': predictions.mean(),
'n_predictions': len(predictions)
}
self.performance_history.append(result)
return result
def monitor_production(self,
production_chunks):
"""
Monitor production data in chunks
Args:
production_chunks: List of DataFrames
one per monitoring period
Returns:
monitoring_results: Performance over time
"""
results = []
print("=" * 55)
print("NannyML — Silent Degradation Monitor")
print("=" * 55)
print(f"{'Period':<10} {'Est. Accuracy':>15} "
f"{'Mean Conf':>12} {'Status':>10}")
print("-" * 55)
for i, chunk in enumerate(production_chunks):
result = self._manual_performance_estimate(
chunk)
if result:
results.append(result)
# Determine status
acc = result['estimated_accuracy']
if acc > 0.75:
status = "✅ GOOD"
elif acc > 0.65:
status = "⚠️ WATCH"
else:
status = "🚨 ALERT"
print(f"{i+1:<10} {acc:>15.4f} "
f"{result['mean_confidence']:>12.4f} "
f"{status:>10}")
print("=" * 55)
return results
def plot_degradation(self, results):
"""
Visualize silent degradation over time
"""
if not results:
return
estimated_accs = [r['estimated_accuracy']
for r in results]
mean_confs = [r['mean_confidence']
for r in results]
fig, axes = plt.subplots(2, 1, figsize=(12, 8))
periods = np.arange(1, len(results) + 1)
axes[0].plot(periods, estimated_accs,
'o-', linewidth=2,
label='Estimated Accuracy (no labels)')
axes[0].axhline(y=0.75, color='green',
linestyle='--',
label='Good threshold (0.75)')
axes[0].axhline(y=0.65, color='red',
linestyle='--',
label='Alert threshold (0.65)')
axes[0].set_ylabel('Estimated Accuracy')
axes[0].set_title('NannyML — Silent Performance '
'Estimation Without Labels')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
axes[1].plot(periods, mean_confs,
's-', linewidth=2,
color='orange',
label='Mean Prediction Confidence')
axes[1].set_ylabel('Mean Confidence')
axes[1].set_xlabel('Monitoring Period')
axes[1].set_title('Confidence Trend — '
'Leading Indicator of Drift')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# Demonstration
np.random.seed(42)
n_features = 8
feature_cols = [f'f{i}' for i in range(n_features)]
# Reference data with labels
reference = pd.DataFrame(
np.random.normal(0, 1, (500, n_features)),
columns=feature_cols)
reference['target'] = np.random.binomial(1, 0.6, 500)
reference['prediction'] = np.clip(
0.4 + 0.4 * reference['target'] + \
np.random.normal(0, 0.1, 500), 0.01, 0.99)
reference['binary_prediction'] = (
reference['prediction'] > 0.5).astype(int)
detector = NannyMLSilentDriftDetector(
reference_data=reference,
feature_columns=feature_cols,
prediction_column='prediction',
chunk_size=100
)
# Simulate production chunks with gradual degradation
production_chunks = []
for period in range(8):
degradation = period * 0.03
n = 100
# Features shift
X = np.random.normal(
degradation, 1, (n, n_features))
chunk = pd.DataFrame(X, columns=feature_cols)
# Predictions become less confident
chunk['prediction'] = np.clip(
np.random.normal(
0.55 - degradation * 0.5,
0.1 + degradation * 0.05, n),
0.01, 0.99)
chunk['binary_prediction'] = (
chunk['prediction'] > 0.5).astype(int)
production_chunks.append(chunk)
results = detector.monitor_production(production_chunks)
detector.plot_degradation(results)What the code does: NannyML solves the most challenging Axis 3 problem — detecting model degradation when you have no ground truth labels for recent predictions. This is the normal situation in production AI: you make predictions now but might not get labels for days, weeks, or never. NannyML’s Confidence-Based Performance Estimation uses the mathematical relationship between prediction confidence and expected accuracy to estimate how well the model is performing right now, without any labels. The production monitoring loop processes data in chunks — each chunk represents one monitoring period — and generates an alert when estimated performance drops below thresholds.
What the math means:The key insight behind CBPE is that the expected accuracy of a binary classifier on a prediction p is max(p,1−p). A prediction of 0.95 will be correct about 95% of the time on average (assuming the model is calibrated). By averaging this over all recent predictions, you get an estimate of current accuracy without any labels. This is only valid when the model is well-calibrated — which is exactly why Axis 2 (Bias Correction) must come before Axis 3 (Drift Detection) in the PCE framework.
With River, Evidently, and NannyML in place, the Axis 3 layer of the PCE Practitioner Toolkit is complete.
Complete PCE Pipeline — All Libraries Together
The complete PCE Practitioner Toolkit pipeline integrates all eight libraries into a single unified control system.
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import entropy
from scipy.special import softmax
from scipy import stats
class CompletePCEPipeline:
"""
Full PCE Practitioner Toolkit
integrating all three axes
Axis 1: NumPy + SciPy + PyTorch
Axis 2: Scikit-learn + Netcal
Axis 3: River + Evidently + NannyML
"""
def __init__(self,
target_entropy=3.0,
bias_threshold=0.05,
drift_threshold=0.3,
vocab_size=1000):
self.target_entropy = target_entropy
self.bias_threshold = bias_threshold
self.drift_threshold = drift_threshold
self.vocab_size = vocab_size
# Axis 1 state
self.temperature = 1.0
self.entropy_errors = []
# Axis 2 state
self.confidence_buffer = []
self.accuracy_buffer = []
self.calibration_temp = 1.0
self.ece_history = []
# Axis 3 state
self.quality_buffer = []
self.reference_stats = None
self.drift_scores = []
self.drift_alarms = []
# Kalman filter for Axis 3
self.kf_state = 0.0
self.kf_P = 1.0
self.kf_Q = 0.001
self.kf_R = 0.1
# System health
self.health_log = []
def axis1_update(self, logits, kp=0.3, ki=0.05):
"""Entropy reduction — temperature control"""
probs = softmax(logits / self.temperature)
H = entropy(probs, base=2)
error = H - self.target_entropy
self.entropy_errors.append(error)
integral = np.mean(
self.entropy_errors[-20:]) if \
len(self.entropy_errors) >= 20 else error
adjustment = kp * error + ki * integral
self.temperature = np.clip(
self.temperature - adjustment, 0.1, 3.0)
return {'entropy': H,
'temperature': self.temperature,
'error': error}
def axis2_update(self, confidence,
outcome, lr=0.02):
"""Bias correction — calibration control"""
self.confidence_buffer.append(confidence)
self.accuracy_buffer.append(outcome)
if len(self.confidence_buffer) >= 20:
recent_conf = np.mean(
self.confidence_buffer[-20:])
recent_acc = np.mean(
self.accuracy_buffer[-20:])
bias = recent_conf - recent_acc
ece_approx = abs(bias)
self.ece_history.append(ece_approx)
if abs(bias) > self.bias_threshold:
correction = -lr * bias
self.calibration_temp = np.clip(
self.calibration_temp * (1 + correction),
0.5, 2.0)
return {'bias': bias,
'ece': ece_approx,
'cal_temp': self.calibration_temp}
return {'bias': 0.0, 'ece': 0.0,
'cal_temp': self.calibration_temp}
def axis3_update(self, quality_score):
"""Drift detection — Kalman-filtered monitoring"""
self.quality_buffer.append(quality_score)
if len(self.quality_buffer) == 50:
self.reference_stats = {
'mean': np.mean(self.quality_buffer),
'std': np.std(self.quality_buffer)
}
if self.reference_stats is None:
return {'drift': False, 'score': 0.0}
z = abs(quality_score -
self.reference_stats['mean']) / \
max(self.reference_stats['std'], 1e-8)
# Kalman filter
P_pred = self.kf_P + self.kf_Q
K = P_pred / (P_pred + self.kf_R)
self.kf_state += K * (z - self.kf_state)
self.kf_P = (1 - K) * P_pred
drift_detected = self.kf_state > \
self.drift_threshold * 3
self.drift_scores.append(self.kf_state)
self.drift_alarms.append(drift_detected)
return {'drift': drift_detected,
'score': self.kf_state,
'z': z}
def step(self, logits, confidence,
outcome, quality_score):
"""
Single complete PCE control step
All three axes simultaneously
"""
a1 = self.axis1_update(logits)
a2 = self.axis2_update(confidence, outcome)
a3 = self.axis3_update(quality_score)
# System health assessment
health = 'CRITICAL' if a3['drift'] else \
'WARNING' if abs(
a2.get('bias', 0)) > \
self.bias_threshold * 2 else \
'HEALTHY'
status = {
'axis1': a1,
'axis2': a2,
'axis3': a3,
'health': health
}
self.health_log.append(health)
return status
def run(self, n_steps=300):
"""Run complete PCE simulation"""
np.random.seed(42)
axis1_metrics = []
axis2_metrics = []
axis3_metrics = []
for step in range(n_steps):
# Simulate system conditions
if step < 100:
uncertainty = 1.0
acc_rate = 0.75
quality = np.random.normal(0.78, 0.04)
elif step < 200:
uncertainty = 1.8
acc_rate = 0.58
quality = np.random.normal(0.60, 0.07)
else:
uncertainty = 1.3
acc_rate = 0.68
quality = np.random.normal(0.70, 0.05)
logits = np.random.randn(
self.vocab_size) * uncertainty
confidence = np.clip(
np.random.normal(acc_rate + 0.1, 0.1),
0.01, 0.99)
outcome = np.random.binomial(1, acc_rate)
status = self.step(
logits, confidence, outcome, quality)
axis1_metrics.append(
status['axis1']['entropy'])
axis2_metrics.append(
status['axis2'].get('bias', 0))
axis3_metrics.append(
status['axis3']['score'])
self._plot_results(
axis1_metrics, axis2_metrics, axis3_metrics)
self._print_summary()
def _plot_results(self, a1, a2, a3):
fig, axes = plt.subplots(3, 1, figsize=(14, 12))
steps = np.arange(len(a1))
axes[0].plot(steps, a1, linewidth=1.5,
color='steelblue')
axes[0].axhline(y=self.target_entropy,
color='red', linestyle='--',
label=f'Target = {self.target_entropy}')
axes[0].set_ylabel('Entropy (bits)')
axes[0].set_title('Axis 1 — Entropy Reduction')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
axes[1].plot(steps, a2, linewidth=1.5,
color='orange')
axes[1].axhline(y=0, color='black',
linestyle='--')
axes[1].axhline(y=self.bias_threshold,
color='red', linestyle=':',
label='Threshold')
axes[1].axhline(y=-self.bias_threshold,
color='red', linestyle=':')
axes[1].set_ylabel('Bias')
axes[1].set_title('Axis 2 — Bias Correction')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
axes[2].plot(steps[50:], a3[50:],
linewidth=1.5, color='purple')
axes[2].axhline(y=self.drift_threshold * 3,
color='red', linestyle='--',
label='Alarm threshold')
axes[2].set_ylabel('Drift Score')
axes[2].set_xlabel('Time Step')
axes[2].set_title('Axis 3 — Drift Detection')
axes[2].legend()
axes[2].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
def _print_summary(self):
health_counts = {
'HEALTHY': self.health_log.count('HEALTHY'),
'WARNING': self.health_log.count('WARNING'),
'CRITICAL': self.health_log.count('CRITICAL')
}
print("\n" + "=" * 50)
print("Complete PCE Pipeline Summary")
print("=" * 50)
print(f"Total steps: {len(self.health_log)}")
for status, count in health_counts.items():
pct = count / len(self.health_log) * 100
print(f"{status:<12}: {count:>5} steps "
f"({pct:.1f}%)")
if self.ece_history:
print(f"Mean ECE: {np.mean(self.ece_history):.4f}")
if self.drift_scores:
print(f"Max drift: {max(self.drift_scores):.4f}")
print("=" * 50)
# Run complete pipeline
pipeline = CompletePCEPipeline(
target_entropy=3.0,
bias_threshold=0.05,
drift_threshold=0.3,
vocab_size=500
)
pipeline.run(n_steps=300)What the code does: The CompletePCEPipeline integrates all three axes into a single unified system that runs continuously. Each call to step() executes one complete PCE control cycle — measuring entropy and adjusting temperature, measuring bias and adjusting calibration, measuring drift and updating the Kalman filter estimate. The health assessment at each step gives a simple three-level status — HEALTHY, WARNING, CRITICAL — that maps directly to operational responses. The summary at the end shows what proportion of production time was spent in each health state.
What the math means:The complete PCE state vector at any time step t is:
And the complete control vector is:
The three axes are orthogonal — each controls a different dimension of system behavior. This orthogonality is what makes PCE powerful: you can fix entropy without touching bias, correct bias without affecting drift detection, and detect drift without perturbing the entropy or bias controllers.
Running all three axes simultaneously is what separates the PCE Practitioner Toolkit from a collection of individual monitoring tools
The PCE Practitioner Toolkit pipeline gives you a single health status — HEALTHY, WARNING, or CRITICAL — at every time step.
Installation Guide
Installing the complete PCE Practitioner Toolkit requires one pip command per axis.
# Core PCE Toolkit — All Libraries
# Axis 1 — Entropy Reduction
pip install numpy scipy torch torchvision
# Axis 2 — Bias Correction
pip install scikit-learn netcal
# Axis 3 — Drift Detection
pip install river evidently nannyml
# Data & Visualization
pip install pandas matplotlib seaborn
# Complete installation in one command
pip install numpy scipy torch scikit-learn \
netcal river evidently nannyml \
pandas matplotlib seaborn
# Verify installation
python -c "
import numpy as np
import scipy
import torch
import sklearn
print('Axis 1 libraries: OK')
from netcal.metrics import ECE
print('Axis 2 libraries: OK')
import river
import evidently
import nannyml
print('Axis 3 libraries: OK')
print('PCE Toolkit fully installed!')
"Library Version Reference (2026):
| Library | Version | Axis | Primary Use |
|---|---|---|---|
| NumPy | 1.26+ | 1 | Entropy computation |
| SciPy | 1.12+ | 1,3 | Distributions, KS test |
| PyTorch | 2.3+ | 1 | Differentiable entropy |
| Scikit-learn | 1.5+ | 2 | Calibration baseline |
| Netcal | 1.3+ | 2 | Neural calibration |
| River | 0.21+ | 3 | Online drift detection |
| Evidently | 0.4+ | 3 | Production monitoring |
| NannyML | 0.10+ | 3 | Label-free monitoring |
The full PCE Practitioner Toolkit can be verified with a single Python import check.
Conclusion
The gap between AI research and production AI engineering comes down to one thing — most engineers know how to build models, but very few know how to control them systematically once they are deployed.
The libraries in this guide are not interesting because they are new. They are interesting because together they implement a complete engineering control system for Generative AI — the first time most AI engineers will have had access to such a toolkit explicitly framed around controllability rather than just performance.
NumPy and SciPy give you the mathematical foundation. PyTorch Distributions gives you entropy control that integrates into training. Scikit-learn and Netcal give you systematic bias measurement and correction. River, Evidently, and NannyML give you the production monitoring infrastructure that catches drift before users notice it.
Together they implement the three axes of Probabilistic Control Engineering — Entropy Reduction, Bias Correction, and Drift Detection — with mature, production-tested code. That is the PCE Practitioner Toolkit. Use it.
Engineers who master this toolkit are well on their way to becoming PCE Practitioners — the new generation of AI control engineers.
What is the PCE Practitioner Toolkit and why do AI engineers need it?
Start with NumPy plus SciPy for Axis 1, scikit-learn for Axis 2, and River for Axis 3. These three cover the core functionality of each axis with minimal installation overhead. Netcal, Evidently, and NannyML are production upgrades that add significant capability when you are ready.
Which library in the PCE Practitioner Toolkit is most important for production?
NannyML is arguably the most strategically important because it solves the label-free monitoring problem — detecting model degradation when you have no ground truth for recent predictions. This is the normal production situation and it is the problem most engineers ignore until something breaks.
Does PyTorch in the PCE Practitioner Toolkit work with Hugging Face models?
Yes — Hugging Face models output logits that can be passed directly to torch.distributions.Categorical. The temperature scaling and entropy computation work on any logit tensor regardless of which transformer architecture produced it.
How often should Evidently run drift checks in the PCE Practitioner Toolkit pipeline?
Daily for most applications. Hourly for high-stakes applications like fraud detection or medical AI. Weekly for stable, low-traffic models. The chunk size parameter controls how many predictions are analyzed per check — larger chunks give more statistically reliable results but slower detection.
Do I need all eight libraries or can I start with fewer in the PCE Practitioner Toolkit?
Yes — these libraries operate on model outputs, not on the model itself. Any system that produces token probabilities, confidence scores, or quality metrics can be monitored with this toolkit regardless of whether it was built with LangChain, LlamaIndex, or any other framework.
What is the difference between River ADWIN and Page-Hinkley in the PCE Practitioner Toolkit?
ADWIN detects gradual drift by comparing the statistics of two adaptive windows — it is best when drift happens slowly over many steps. Page-Hinkley detects abrupt changes by accumulating evidence of a mean shift — it is best when drift happens suddenly. Running both simultaneously catches more drift patterns than either alone.
Is Netcal in the PCE Practitioner Toolkit compatible with PyTorch and TensorFlow?
Netcal works with probability arrays from any source — it does not care whether the model was built in PyTorch, TensorFlow, or scikit-learn. You pass in confidence scores and labels, and it returns calibrated scores. Framework agnostic.
How do I know if my model needs bias correction from the PCE Practitioner Toolkit?
Compute the Expected Calibration Error on a holdout set. If ECE exceeds 0.05 — meaning confidence and accuracy differ by more than 5 percentage points on average — bias correction is needed. Most neural networks without calibration have ECE between 0.10 and 0.20.
What happens when drift is detected using the PCE Practitioner Toolkit?
Three options depending on severity. Minor drift — retrain on recent data. Moderate drift — switch to a more recent model version. Severe drift — fall back to a simpler model or rule-based system while retraining happens. The PCE framework does not specify the response — it specifies the detection. Response policy depends on your application’s risk tolerance.
Are there GPU-accelerated versions of the PCE Practitioner Toolkit drift detection libraries?
River and NannyML are CPU-only — drift detection computations are lightweight enough that GPU acceleration is not needed. Evidently is also CPU-based. PyTorch Distributions for Axis 1 is fully GPU-accelerated and should be run on GPU when processing large batches of logits.